 A developer is responsible for using any and all techniques to make sure that he produces defect free code. The average developer does not take advantage of all of the following opportunities to prevent and eliminate defects:
A developer is responsible for using any and all techniques to make sure that he produces defect free code. The average developer does not take advantage of all of the following opportunities to prevent and eliminate defects:
- Before the code is written
- As the code is written
- Writing mechanisms for early detection
- Before the code is executed
- After the code is tested
The technique that is used most often is #5 above and will not be covered here. It involves the following:

- Code is delivered to the test department
- The test department identifies defects and notifies development
- Developer’s fire up the debugger and try to chase down the defect
 Like the ‘rinse and repeat‘ process on a shampoo bottle, this process is repeated until the code is cleaned or until you run out of time and are forced to deliver.
Like the ‘rinse and repeat‘ process on a shampoo bottle, this process is repeated until the code is cleaned or until you run out of time and are forced to deliver.
The almost ubiquitous use of #5 leads to CIOs and VPs of Engineering assuming that the metric of one tester to two developers is a good thing. Before assuming that #5 is ‘the way to go‘ consider the other techniques and statistical evidence of their effectiveness.
Before the Code is Written
A developer has the most options available to him before the code is written. The developer has an opportunity to plan his code, however, there are many developers who just ‘start coding’ on the assumption that they can fix it later.
developer has an opportunity to plan his code, however, there are many developers who just ‘start coding’ on the assumption that they can fix it later.
How much of an effect can planning have? Two methodologies that focus directly on planning at the personal and team level are the Personal Software Process (PSP) and the Team Software Process (TSP) invented by Watts Humphrey.
PSP can raise productivity by 21.2% and quality by 31.2%
TSP can raise productivity by 20.9% and quality by 30.9%
Not only does the PSP focus on code planning, it also makes developers aware of how many defects they actually create. Here are two graphs that show the same group of developers and their defect injection rates before and after PSP training.
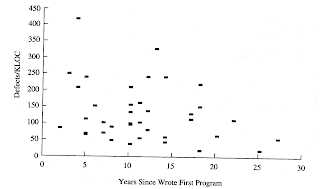 |
 |
| Before PSP training |
After PSP training |
The other planning techniques are:
- Decision tables
- Proper use of exceptions
Both are covered in the article Debuggers are for Losers and will not be covered here.
As the Code is Written
 Many developers today use advanced IDEs to avoid common syntax errors from occurring If you can not use such an IDE or the IDE does not provide that service then some of the techniques in the PSP can be used to track your injection of syntax errors and reduce those errors.
Many developers today use advanced IDEs to avoid common syntax errors from occurring If you can not use such an IDE or the IDE does not provide that service then some of the techniques in the PSP can be used to track your injection of syntax errors and reduce those errors.
Pair Programming
One technique that can be used while code is being written is Pair Programming. Pair programming is heavily used in eXtreme Programing (XP). Pair programming not only allows code to be reviewed by a peer right away but also makes sure that there are two people who understand the code pathways through any section of code.
Pair programming is not cost effective overall (see Capers Jones). For example, it makes little sense to pair program code that is mainly boiler plate, i.e. getter and setter classes. What does make sense is that during code planning it will become clear which routines are more involved and which ones are not. If the cyclomatic complexity of a routine is high (>15) then it makes sense for pair programming to be used.
If used for all development, Pair Programming can raise productivity by 2.7% and quality by 4.5%
Test Driven Development

Test driven development (TDD) is advocated by Kent Beck and stated in 2003 that TDD encourages simple designs and inspires confidence. TDD fits into the category of automated unit testing.
Automated unit testing can raise productivity by 16.5% and quality by 23.7%
Writing Mechanisms for Early Detection
Defects are caused by programs either computing wrong values, going down the wrong pathway, or both. The nature of defects is that they tend to cascade and get bigger the further in time and space between the source of the defect and the noticeable effects of the defect.
Design By Contract
One way to build checkpoints into code is to use Design By Contract (DbC), a technique that was pioneered by the Eiffel programming language It would be tedious and overkill to use DbC in every routine in a program, however, there are key points in every software program that get used very frequently.
that was pioneered by the Eiffel programming language It would be tedious and overkill to use DbC in every routine in a program, however, there are key points in every software program that get used very frequently.
Just like the roads that we use have highways, secondary roads, and tertiary roads — DbC can be used on those highways and secondary roads to catch incorrect conditions and stop defects from being detected far away from the source of the problem.
Clearly very few of us program in Eiffel. If you have access to Aspect Oriented Programming (AOP) then you can implement DbC via AOP. Today there are AOP implementations as a language extension or as a library for many current languages (Java, .NET, C++, PHP, Perl, Python, Ruby, etc).
Before the Code is Executed
Static Analysis
Most programming languages out there lend themselves to static analysis. There are cost effective static analysis for virtually every language.
Automated static analysis can raise productivity by 20.9% and quality by 30.9%
Inspections

Of all the techniques mentioned above, the most potent pre-debugger technique is inspections. inspections are not sexy and they are very low tech, but the result of organizations that do software inspections borders on miraculous.The power of software inspections can be seen in these two articles:
Code inspections can raise productivity by 20.8% and quality by 30.8%
Design inspections can raise productivity by 16.9% and quality by 24.7%
From the Software Inspections book on p.22.
In one large IBM project, one half million lines of networked operating system, there were 11 development stages (document types: logic, test, user documentation) being Inspected. The normal expectation at IBM, at that time, was that they would be happy only to experience about 800 defects in trial site operation. They did in fact experience only 8 field trial defects.
Evidence suggests that every 1 hour of code inspection will reduce testing time by 4 hours
Conclusion
Overworked developers rarely have time to do research, even though it is clear that there is a wealth of information available on how to prevent and eliminate defects. The bottom line is that if your are only using technique #5 from the initial list, then you are not using every technique available to you to go after defects.My opinion only, but:
A professional software developer uses every technique at his disposal to prevent and eliminate defects
Other articles in the “Loser” series
 Want to see more sacred cows get tipped? Check out:
Want to see more sacred cows get tipped? Check out:
Make no mistake, I am the biggest “Loser” of them all. I believe that I have made every mistake in the book at least once 🙂
References
Gilb, Tom and Graham, Dorothy. Software Inspections
Jones, Capers. SCORING AND EVALUATING SOFTWARE METHODS, PRACTICES, AND RESULTS. 2008.
Radice, Ronald A. High Quality Low Cost Software Inspections.
VN:F [1.9.22_1171]
Rating: 0.0/5 (0 votes cast)
VN:F [1.9.22_1171]



 That is why developers that plan their code before using the keyboard tend to outperform other developers. Not only do only a few developers really plan out their code before coding but also years of experience do not teach developers to learn to plan. In fact studies over 40 years show that developer productivity does not change with years of experience. (see No Experience Required!)
That is why developers that plan their code before using the keyboard tend to outperform other developers. Not only do only a few developers really plan out their code before coding but also years of experience do not teach developers to learn to plan. In fact studies over 40 years show that developer productivity does not change with years of experience. (see No Experience Required!) If you are interested there are many other proven methods of raising code quality that are not commonly used (see Not Planning is for Losers).
If you are interested there are many other proven methods of raising code quality that are not commonly used (see Not Planning is for Losers). What the Heck are Non-Functional Requirements?
What the Heck are Non-Functional Requirements?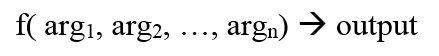
 This is true whether you use an object-oriented language or not. Non-functional requirements involve everything that surrounds a functional code unit. Non-functional requirements concern things that involve time, memory, access, and location:
This is true whether you use an object-oriented language or not. Non-functional requirements involve everything that surrounds a functional code unit. Non-functional requirements concern things that involve time, memory, access, and location: Availability is about making sure that a service is available when it is supposed to be available. Availability is about a
Availability is about making sure that a service is available when it is supposed to be available. Availability is about a  Capacity is about delivering enough functionality when required. If you ask a web service to supply 1,000 requests a second when that server is only capable of 100 requests a second then some requests will get dropped. This may look like an availability issue, but it is caused because you can’t handle the capacity requested.
Capacity is about delivering enough functionality when required. If you ask a web service to supply 1,000 requests a second when that server is only capable of 100 requests a second then some requests will get dropped. This may look like an availability issue, but it is caused because you can’t handle the capacity requested. Continuity involves being able to be robust against major interruptions to a service, these include power outages, floods or fires in an operational center, or any other disaster that can disrupt the network or physical machines.
Continuity involves being able to be robust against major interruptions to a service, these include power outages, floods or fires in an operational center, or any other disaster that can disrupt the network or physical machines.
 Commonly start-ups are so busy setting up their services that the put non-functional requirements on the
Commonly start-ups are so busy setting up their services that the put non-functional requirements on the  Make no mistake, operations and help desk personnel are fairly resourceful and have learned how to manage software where non-functional requirements are not handled by the code. Hardware and OS solutions exist for making up for poorly written software that assumes single machines or does not take into account the environment that the code is running in, but that can come at a fairly
Make no mistake, operations and help desk personnel are fairly resourceful and have learned how to manage software where non-functional requirements are not handled by the code. Hardware and OS solutions exist for making up for poorly written software that assumes single machines or does not take into account the environment that the code is running in, but that can come at a fairly 
 It is common for new releases to have various
It is common for new releases to have various  Similarly, there may be many cosmetic or minor defects where fixing them might make a huge difference in the user experience and reduce support calls. Even though these defects are minor, they may be
Similarly, there may be many cosmetic or minor defects where fixing them might make a huge difference in the user experience and reduce support calls. Even though these defects are minor, they may be  It is very hard to generate meaningful reports when these attributes creep into the defect status. You know that this has happened if you have a multi-page training manual for entering defects into the system. Some of the statuses that make sense initially but turn the defect system into a nightmare are:
It is very hard to generate meaningful reports when these attributes creep into the defect status. You know that this has happened if you have a multi-page training manual for entering defects into the system. Some of the statuses that make sense initially but turn the defect system into a nightmare are: As development progresses we inevitably run into functionality gaps that are either deemed as
As development progresses we inevitably run into functionality gaps that are either deemed as 
 Enhancements may or may not become code changes. Even when enhancements turn into code change requests they will generally not be implemented as the developer or QA think they should be implemented.
Enhancements may or may not become code changes. Even when enhancements turn into code change requests they will generally not be implemented as the developer or QA think they should be implemented. The creation of requirements and test defects in the bug tracker goes a long way to cleaning up the bug tracker. In fact, requirements and test defects represent about 25% of defects in most systems (see
The creation of requirements and test defects in the bug tracker goes a long way to cleaning up the bug tracker. In fact, requirements and test defects represent about 25% of defects in most systems (see 


 The best way to solve all 3 issues is through formal planning and development.Two methodologies that focus directly on planning at the personal and team level are the
The best way to solve all 3 issues is through formal planning and development.Two methodologies that focus directly on planning at the personal and team level are the  Therefore, complexity in software development is about making sure that all the code pathways are accounted for. In increasingly sophisticated software systems the number of code pathways increases exponentially with the call depth. Using formal methods is the only way to account for all the pathways in a sophisticated program; otherwise the number of defects will multiply exponentially and cause your project to fail.
Therefore, complexity in software development is about making sure that all the code pathways are accounted for. In increasingly sophisticated software systems the number of code pathways increases exponentially with the call depth. Using formal methods is the only way to account for all the pathways in a sophisticated program; otherwise the number of defects will multiply exponentially and cause your project to fail.

 Unfortunately, weak IT leadership, internal politics, and embarrassment over poor estimates will not move the deadline and teams will have pressure put on them by overbearing senior executives to get to the original deadline even though that is not possible.
Unfortunately, weak IT leadership, internal politics, and embarrassment over poor estimates will not move the deadline and teams will have pressure put on them by overbearing senior executives to get to the original deadline even though that is not possible. Work executed on these activities will not advance your project and should not be counted in the total of completed hours. So if 2,000 hours have been spent on activities that don’t advance the project then if 9,000 hours have been done on a 10,000 hour project then you have really done 7,000 hours of the 10,000 hour project and
Work executed on these activities will not advance your project and should not be counted in the total of completed hours. So if 2,000 hours have been spent on activities that don’t advance the project then if 9,000 hours have been done on a 10,000 hour project then you have really done 7,000 hours of the 10,000 hour project and 





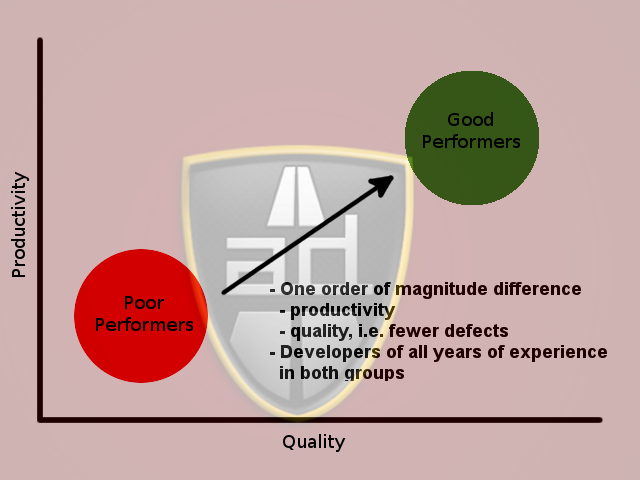 That is the worst programmers and the best programmers made distinct groups and each group had people of low and high experience levels. Whether training helps developers or not is not indicated by these findings, only that years of experience do not matter.
That is the worst programmers and the best programmers made distinct groups and each group had people of low and high experience levels. Whether training helps developers or not is not indicated by these findings, only that years of experience do not matter.




 Quality Assurance (QA) is about making a positive statement about product quality. QA is about positive assurance, which is stating, “
Quality Assurance (QA) is about making a positive statement about product quality. QA is about positive assurance, which is stating, “ The reality is that most testing departments simply discover defects and forward them back to the engineering department to fix. By the time the software product gets released we are basically saying, “
The reality is that most testing departments simply discover defects and forward them back to the engineering department to fix. By the time the software product gets released we are basically saying, “ Everyone understand that buggy software kills sales (and start-ups :-)), however, testing is often an after thought in many organizations. When software products take longer than expected they are forwarded to the testing department. The testing department is often expected to test and bless code in less time than allocated.
Everyone understand that buggy software kills sales (and start-ups :-)), however, testing is often an after thought in many organizations. When software products take longer than expected they are forwarded to the testing department. The testing department is often expected to test and bless code in less time than allocated. Properly written tests require a developer not only to think about what a code section is supposed to do but also plan how the code will be structured. If you know that there are five pathways through the code then you will write five tests ahead of time. A common problem is that you have coded n paths through the code when there are n+1 conditions.
Properly written tests require a developer not only to think about what a code section is supposed to do but also plan how the code will be structured. If you know that there are five pathways through the code then you will write five tests ahead of time. A common problem is that you have coded n paths through the code when there are n+1 conditions.
 Since the 1970s we have statistical evidence that one of the best ways to eliminate defects from code is through inspections. Inspections can be applied to the requirements, design, and code artifacts and projects that use inspections can eliminate 99% of the defects injected into the code. Se
Since the 1970s we have statistical evidence that one of the best ways to eliminate defects from code is through inspections. Inspections can be applied to the requirements, design, and code artifacts and projects that use inspections can eliminate 99% of the defects injected into the code. Se  There is
There is  are the best line of defense to remove them. The developer has the best information on what needs to be tested in his code at the time that he writes it. The longer it takes for testing or a customer to discover a code defect the longer the developer will spend in a debugger chasing down the problem.
are the best line of defense to remove them. The developer has the best information on what needs to be tested in his code at the time that he writes it. The longer it takes for testing or a customer to discover a code defect the longer the developer will spend in a debugger chasing down the problem.