 Every developer is aware that code inspections are possible, some might have experienced the usefulness of code inspections, however, the fact is that inspections are not optional.
Every developer is aware that code inspections are possible, some might have experienced the usefulness of code inspections, however, the fact is that inspections are not optional.
Without inspections your defect removal rate will stall out at 85% of defects removed; with inspections defect removal rates of 97% have been achieved.
Code inspections are only the most talked about type of inspection; the reality is that all artifacts from all phases of development should be inspected prior to being used. Inspections are necessary because software is intangible and it is not once everything is coded that you want to notice problems.
 In the physical world it is easier to spot problems because they can be tangible. For example, if you have specified marble tiles for your bathroom and you see the contractor bring in a pile of ceramic tiles then you know something is wrong. You don’t need the contractor to install the ceramic tiles to realize that there is a problem.
In the physical world it is easier to spot problems because they can be tangible. For example, if you have specified marble tiles for your bathroom and you see the contractor bring in a pile of ceramic tiles then you know something is wrong. You don’t need the contractor to install the ceramic tiles to realize that there is a problem.
In software, we tend to code up an entire set of functionality, demonstrate it, and then find out that we have built the wrong thing! If you are working in a domain with many requirements then this is inevitable, however, many times we can find problems through inspection before we create the wrong solutions
Let’s look at some physical examples and then discuss their software equivalents.
Requirement Defects
The requirements in software design are equivalent to the blueprints that are given to a contractor. The requirements specify the system to be built, however, if those requirements are not inspected then you can end up with the following:
| Balcony no Door |
Missing Landing |
Chimney Covering Window |
 |
 |
 |
| Stairs Displaced |
Stairs to Ceiling |
Door no Balcony/th> |
 |
 |
 |
All of the above pictures represent physical engineering failures. Every one of these disasters could have been identified in the blueprints if a simple inspection had been done. Clearly it must have become clear to the developers that the building features specified by the requirements were incompatible, but they completed the solution anyways.
Balcony no Door
 This design flaws can be caused by changing requirements; here there is a balcony feature that has no access to it. In Balcony no Door it is possible that someone noticed that there was sufficient room for a balcony on the lower floor and put it into one set of plans. The problem was that the developers that install the sliding doors did not have their plans updated.
This design flaws can be caused by changing requirements; here there is a balcony feature that has no access to it. In Balcony no Door it is possible that someone noticed that there was sufficient room for a balcony on the lower floor and put it into one set of plans. The problem was that the developers that install the sliding doors did not have their plans updated.
Here the changed requirement did not lead to an inspection to see if there was an inconsistency introduced by the change.
Door no Balcony
 In Door no Balcony something similar probably happened, however, notice that the two issues are not symmetric. In Balcony no Door represents a feature that is inaccessible because no access was created, i.e. the missing sliding door. In Door no Balcony we have a feature that is accessible but dangerous if used.
In Door no Balcony something similar probably happened, however, notice that the two issues are not symmetric. In Balcony no Door represents a feature that is inaccessible because no access was created, i.e. the missing sliding door. In Door no Balcony we have a feature that is accessible but dangerous if used.
In this case a requirements inspection should have turned up the half implemented feature and either: 1) the door should have been removed from the requirements, or 2) a balcony should have been added.
Missing Landing
 The Missing Landing occurs because the requirements show a need for stairs, but does not occur to the architect that there is a missing landing. Looking at a set of blueprints gives you a two dimensional view of the plan and clearly they drew in the stairs. To make the stairs usable requires a landing so that changing direction is simple. This represents a missing requirement that causes another feature to be only partially usable.
The Missing Landing occurs because the requirements show a need for stairs, but does not occur to the architect that there is a missing landing. Looking at a set of blueprints gives you a two dimensional view of the plan and clearly they drew in the stairs. To make the stairs usable requires a landing so that changing direction is simple. This represents a missing requirement that causes another feature to be only partially usable.
This problem should have been caught by the architect when the blueprint was drawn up. However, barring the architect locating the issue a simple checklist and inspection of the plans would have turned up the problem.
Stairs to Ceiling
 The staircase goes up to a ceiling and therefore is a useless feature. Not only is the feature incomplete because it does not give access to the next level but also they developers wasted time and effort in building the staircase.
The staircase goes up to a ceiling and therefore is a useless feature. Not only is the feature incomplete because it does not give access to the next level but also they developers wasted time and effort in building the staircase.
If this problem had been caught in the requirements stage as an inconsistency then either the staircase could have been removed or an access created to the next floor. The net effect is that construction starts and the developers find the inconsistency when it is too late.
At a minimum the developers should have noticed that the stairway did not serve any purpose and not build the staircase which was a waste of time and materials.
Stairs Displaced
 Here we have a clear case of changed requirements. The stairs were supposed to be centered under the door, in all likelihood plans changed the location of the door and did not move the dependent feature.
Here we have a clear case of changed requirements. The stairs were supposed to be centered under the door, in all likelihood plans changed the location of the door and did not move the dependent feature.
When the blueprint was updated to move the door the designer should have looked to see if there was any other dependent feature that would be impacted by the change.
Architectural Defects
Architectural defects come from not understanding the requirements or the environment that you are working with. In software, you need to understand the non-functional requirements behind the functional requirements — the ilities of the project (availability, scalability, reliability, customizability, stability, etc).
Architectural features are structural and connective. In a building the internal structure must be strong enough to support the building, i.e. foundation and load bearing walls.
| insufficient foundation |
Insufficient structure |
Connectivity problem |
 |
 |
 |
Insufficient Foundation
Here the building was built correctly, however, the architect did not check the environment to see if the foundation would be sufficient for the building. The building is identical to the building behind it, so odds are they just duplicated the plan without checking the ground structure.
The equivalent in software is to design for an environment that can not support the functionality that you have designed. Even if that functionality is perfect, if the environment doesn’t support it you will not succeed.
Insufficient Structure
Here the environment is sufficient to hold up the building, however, the architect did not design enough structural strength in the building.
The equivalent in software design is to choose architectural components that will not handle the load demanded by the system. For example, distributed object technologies such as CORBA, EJB, and DCOM provided a way to make objects available remotely, however, the resulting architectures did not scale well under load.
Connectivity Problem
Here a calculation error was made when the two sides of the bridge were started. When development got to the center they discovered that one side was off and you have an ugly problem joining the two sides.
The equivalent for this problem is when technologies don’t quite line up and require awkward and ugly techniques to join different philosophical approaches.
In software, a classic problem is mapping object-oriented structures into relational databases. The philosophical mismatch accounts for large amounts of code to translate from one scheme into the other.
Coding Defects
 Coding defects are better understood (or at least yelled about :-), so I won’t spend too much time on them. Classic coding defects include:
Coding defects are better understood (or at least yelled about :-), so I won’t spend too much time on them. Classic coding defects include:
- Uninitialized data
- Uncaught exceptions
- Memory leaks
- Buffer overruns
- Not freeing up resources
- Concurrency violations
- Insufficient pathways, i.e. 5 conditions but only 4 coded pathway
Many of these problems can be caught with code inspections.
Testing Defects
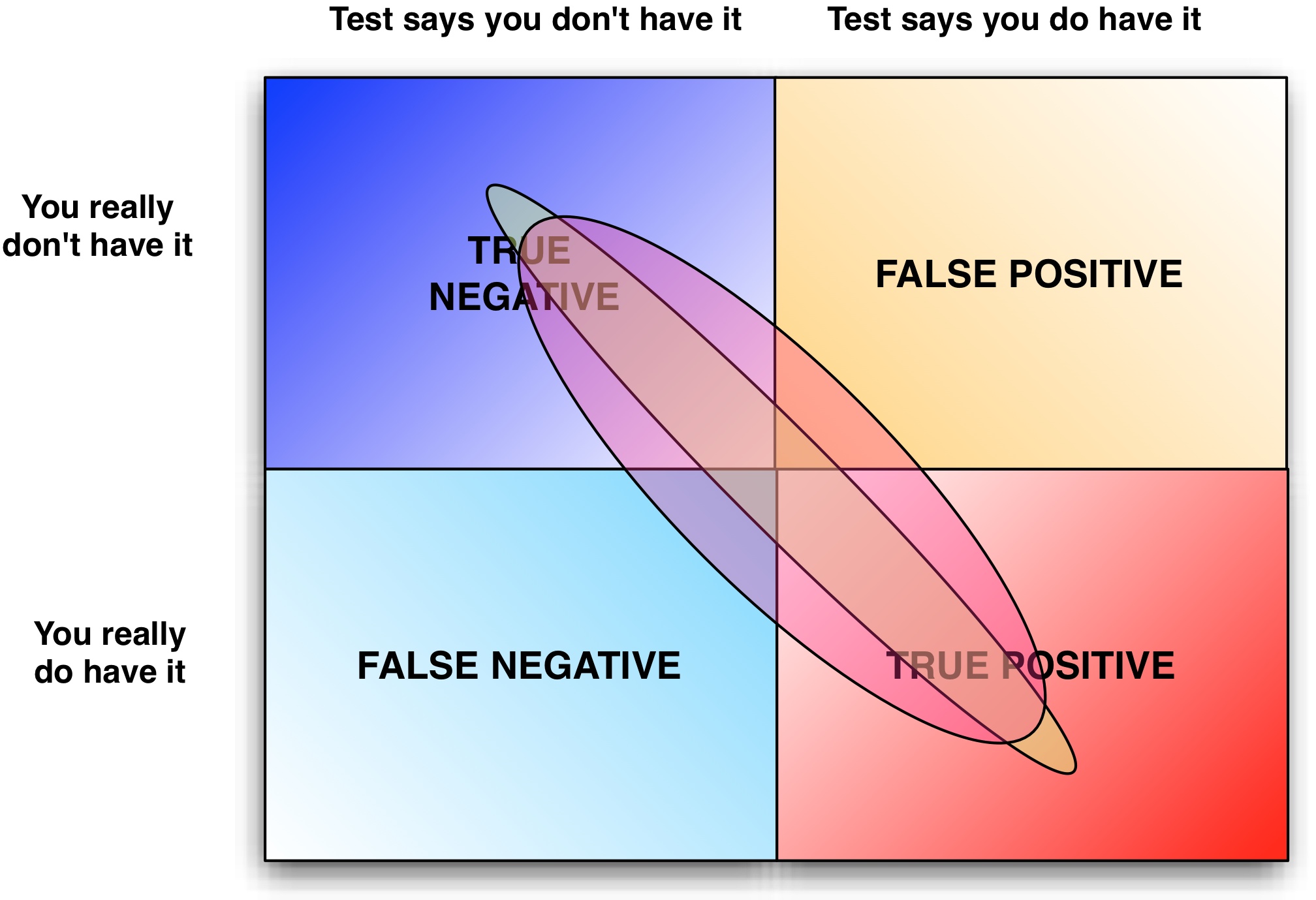 Testing defects occur when the test plan flags a defect that is a phantom problem or a false positive. This often occurs when requirements are poorly documented and/or poorly understood and QA perceives a defect when there is none.
Testing defects occur when the test plan flags a defect that is a phantom problem or a false positive. This often occurs when requirements are poorly documented and/or poorly understood and QA perceives a defect when there is none.
The reverse also happens where requirements are not documented and QA does not perceive a defect, i.e. false negative.
Both false positives and negatives can be caught by inspecting the requirements and comparing them with the test cases.
False positives slow down development. False negatives can slip through to your customers…
Root Cause of Firefighting
When inspections are not done in all phases of software development there will be fire-fighting in the project in the zone of chaos. Most software organizations only record and test for defects during the Testing phase. Unfortunately, at this point you will detect defects in all previous phases at this point.

QA has a tendency to assume that all defects are coding defects — however, the analysis of 18,000+ projects does not confirm this. In The Economics of Software Quality, Capers Jones and Olivier Bonsignour show that defects fall into different categories. Below we give the category, the frequency of the defect, and the business role that will address the defect.
Note, only the bolded rows below are assigned to developers.
| Defect Role Category |
Frequency |
Role |
| Requirements defect |
9.58% |
BA/Product Management |
| Architecture or design defect |
14.58% |
Architect |
| Code defect |
16.67% |
Developer |
| Testing defect |
15.42% |
Quality Assurance |
| Documentation defect |
6.25% |
Technical Writer |
| Database defect |
22.92% |
DBA |
| Website defect |
14.58% |
Operations/Webmaster |
Notice that fully 25% of the defects (requirements, architecture) occur before coding even starts. These defects are just like the physical defects shown above and only manifest themselves once the code needs to be written.
It is much less expensive to fix requirements and architecture problems before coding.
Also, only about 54% of defects are actually resolvable by developers, so by assigning all defects to the developers you will waste time 46% of the time when you discover that the developer can not resolve the issue.
 Fire-fighting is basically when there need to be dozens of meetings that pull together large numbers of people on the team to sort out inconsistencies. These inconsistencies will lie dormant because there are no inspections. Of course, when all the issues come out, there are so many issues from all the phases of development that it is difficult to sort out the problem!
Fire-fighting is basically when there need to be dozens of meetings that pull together large numbers of people on the team to sort out inconsistencies. These inconsistencies will lie dormant because there are no inspections. Of course, when all the issues come out, there are so many issues from all the phases of development that it is difficult to sort out the problem!
Learn how to augment your Bug Tracker to help you to understand where your defects are coming from in Bug Tracker Hell and How to Get Out!
Solutions
There are two basic solutions to reducing defects:
- Inspect all artifacts
- Shorten your development cycle
The second solution is the one adopted by organizations that are pursuing Agile software development. However, shorter development cycles will reduce the amount of fire-fighting but they will only improve code quality to a point.
In The Economics of Software Quality the statistics show that defect removal is not effective in most organizations. In fact, on large projects the test coverage will drop below 80% and the defect removal efficiency is rarely above 85%. So even if you are using Agile development you will still not achieving a high level of defect removal and will be limited in the software quality that you can deliver.
Agile development can reduce fire-fighting but does not address defect removal
Inspect All Artifacts
Organizations that have formal inspections of all artifacts have achieved defect removal efficiencies of 97%! If you are intent on delivering high quality software then inspections are not optional.
Of course, inspections are only possible for phases in which you have actual artifacts. Here are the artifacts that may be associated with each phase of development:
| Phase |
Artifact |
| Requirements |
use case, user story, UML Diagrams (Activity, Use Case) |
| Architecture or design |
UML diagrams (Class, Interaction, Deployment) |
| Coding |
UML diagrams (Class, Interaction, State, Source Code) |
| Testing |
Test plans and cases |
| Documentation |
Documentation |
| Database |
Entity-Relationship diagrams, Stored Procedures |
Effective Inspections
Inspections are only effective when the review process involves people who know what they are looking for and are accountable for the result of the inspection. People must be trained to understand what they are looking for and effective check lists need to be developed for each artifact type that you review, e.g. use case inspections will be different than source code reviews.
Inspections must have teeth otherwise they are a waste of time. For example, one way to put accountability into the process is to have someone other than the author be accountable for any problems found. There are numerous resources available if you decide that you wish to do inspections.
Conclusion
The statistics overwhelming suggest that inspections will not only remove defects from a software system but also prevent defects from getting in. With inspections software defect removal rates can achieve 97% and without inspections you are lucky to get to 85%.
Since IBM investigated the issue in 1973, it is interesting to note that teams trained in performing inspections eventually learn how to prevent injecting defects into the software system. Reduced injection of defects into a system reduces the amount of time spent in fire-fighting and in QA.
You can only inspect artifacts that you take the time to create. Many smaller organizations don’t have any artifacts other than their requirements documents and source code. Discover which artifacts need to be created by augmenting your Bug Tracker (see Bug Tracker Hell and How To Get Out!). Any phase of development where significant defects are coming from should be documented with an appropriate artifact and be subject to inspections.
Good books on how to perform inspections:
All statistics quoted from The Economics of Software Quality by Capers Jones and Olivier Bonsignour:
Capers Jones can be reached by sending me an email: Dalip Mahal
VN:F [1.9.22_1171]
Rating: 0.0/5 (0 votes cast)
VN:F [1.9.22_1171]

 Are you a software professional or not?
Are you a software professional or not? This diagram from Radice shows that defects will accumulate until testing begins. Your quality will be limited by the number of defects that you can find before you ship your software.
This diagram from Radice shows that defects will accumulate until testing begins. Your quality will be limited by the number of defects that you can find before you ship your software.

 The issue is that people know that they make mistakes but don’t want to admit it, i.e. who wants to admit that they put the milk in the cupboard? They certainly don’t want their peers to know about it!
The issue is that people know that they make mistakes but don’t want to admit it, i.e. who wants to admit that they put the milk in the cupboard? They certainly don’t want their peers to know about it! For inspections to work, they must be conducted in a non-judgmental environment where the goal is to eliminate defects and improve quality. When inspections turn into witch hunts and/or the focus is on style rather than on substance then inspections will fail miserably and they will become a waste of time.
For inspections to work, they must be conducted in a non-judgmental environment where the goal is to eliminate defects and improve quality. When inspections turn into witch hunts and/or the focus is on style rather than on substance then inspections will fail miserably and they will become a waste of time.





 What Life Cycle States Do We Need?
What Life Cycle States Do We Need?


 Trust But Verify
Trust But Verify


 Defects should be assigned to a role and not a specific person to allow maximum flexibility in getting the work done; they should only be assigned to a specific person when there is only one person who can resolve an issue.
Defects should be assigned to a role and not a specific person to allow maximum flexibility in getting the work done; they should only be assigned to a specific person when there is only one person who can resolve an issue. I like
I like 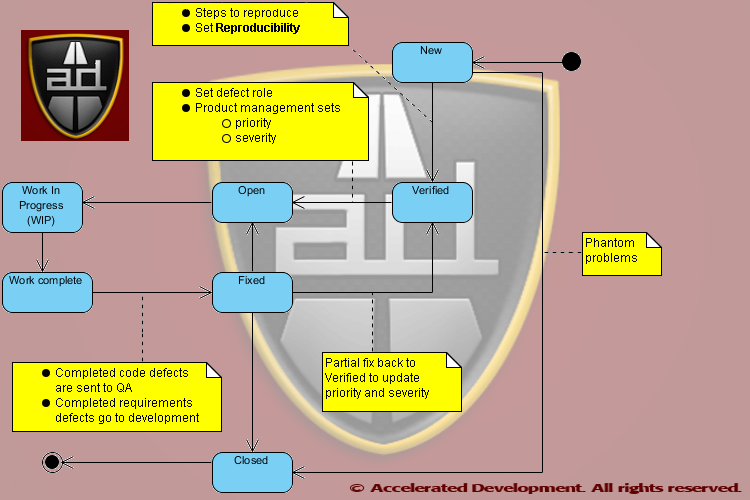

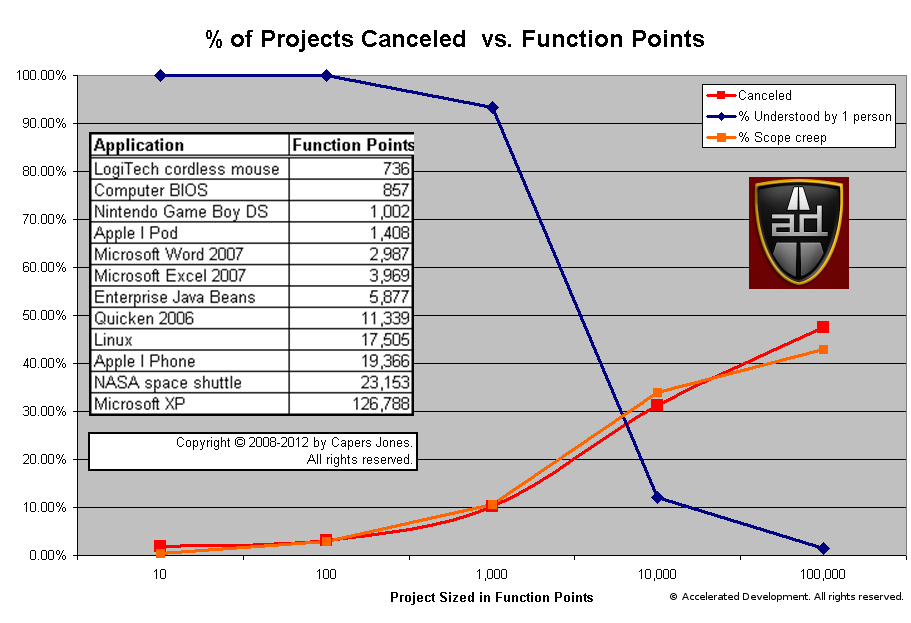 Analysis shows that the probability of a project being canceled is highly correlated with the amount of scope shift. Simply creating enhancements in the Bug Tracker hides this problem and does not help the team.
Analysis shows that the probability of a project being canceled is highly correlated with the amount of scope shift. Simply creating enhancements in the Bug Tracker hides this problem and does not help the team.









