![]() Whether you call it a defect or bug or change request or issue or enhancement you need an application to record and track the life-cycle of these problems. For brevity, let’s call it the Bug Tracker.
Whether you call it a defect or bug or change request or issue or enhancement you need an application to record and track the life-cycle of these problems. For brevity, let’s call it the Bug Tracker.
Bug trackers are like a roach motel, once defects get in they don’t check out! Because they are append only, shouldn’t we be careful and disciplined when we add “tickets” to the bug tracker?  We should, but in the chaos of a release (especially start-ups :-)) the bug tracker goes to hell.
We should, but in the chaos of a release (especially start-ups :-)) the bug tracker goes to hell.
Bug Tracker Hell happens when inconsistent usage of the tool leads to various problems such as duplicate bugs, inconsistent priorities and severities. While 80% of defects are straight forward to add to the Bug Tracker, it is the other 20% of the defects that cause real problems.
The most important attribute of a defect is its DefectLifecycleStatus; not surprisingly every Bug Tracker makes this the primary field for sorting. This primary field is used to generate reports and to manage the defect removal process. If we manage this field carefully we can generate reports that not only help the current version but also provide key feedback for post-mortem analysis.
Every Bug Tracker has at least the states Open, Fixed, and Closed, however, due to special cases we are tempted to create new statuses for problems that have nothing to do with the life cycle. The creation of life cycle statuses that are not life cycle states is what caused inconsistent usage of the tool because then it becomes unclear how to enter a defect.
It is much easier to have consistent life cycle states than to have a 10 page manual on how to enter a defect.
(This color is used to indicate a defect attribute, and this color is used to indicate a constant.)
 What Life Cycle States Do We Need?
What Life Cycle States Do We Need?
Clearly we want to know how many Open defects need to be fixed for the current release; after all, management is often breathing down our neck to get this information.
Ideally we would get the defects outstanding report by finding out how many defects are Open. Unfortunately, there are numerous open defects that will not be fixed in the current release (or ever 🙁 ) and so we seek ways to remove those defects from the defects outstanding.

Why complicate life?
In particular we are tempted to create states like Deferred, WontFix, and FunctionsAsDesigned, to remove defects from the defects outstanding. These states have the apparent effect of simplifying the defects outstanding report but will end up complicating other matters.
For example, Deferred is simply an open defect that is not getting fixed in the current release; WontFix is an open defect that the business has decided not to fix; and FunctionsAsDesigned indicates that either the requirements were faulty or QA saw a phantom problem, but once this defect gets into the Bug Tracker you can’t get it out.
![]() All three states above variants of the Open life cycle state and creating these life cycle states will create more problems than they solve. The focus of this article is on how to fix the defect life cycle, however, other common issues are addressed.
All three states above variants of the Open life cycle state and creating these life cycle states will create more problems than they solve. The focus of this article is on how to fix the defect life cycle, however, other common issues are addressed.
Life cycle states for Deferred, WontFix, or FunctionsAsDesigned is like a “Go directly to Bug Tracker Hell” card!
Each Defect Must Be Unambiguous
The ideal state of a Bug Tracker is to be able to look at any defect in the system and have a clear answer to each of the following questions.
- Where is the defect in the life-cycle?
- Has the problem been verified?
- How consistently can the problem be reproduced or is it intermittent?
- Which team role will resolve the issue? (team role, not person)
The initial way to get out of hell is to be consistent with the life cycle state.
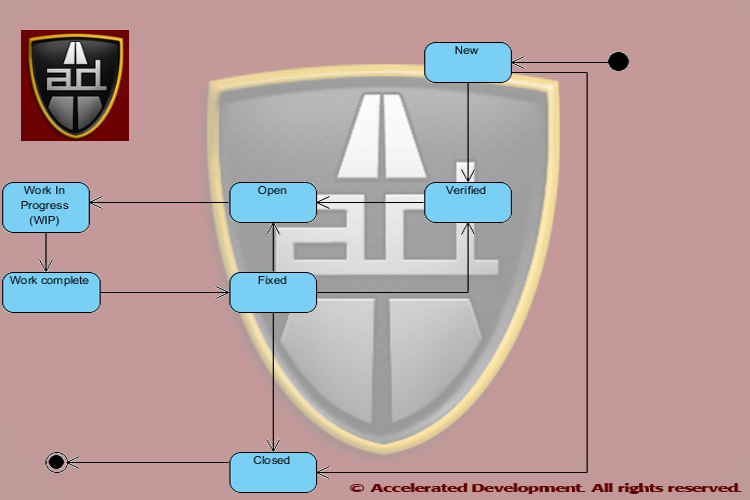
Defect Life Cycle
All defects go through the following life cycle (DefectLifecycleStatus) regardless of whether we track all of these states or not:

- New
- Verified
- Open
- Work in Process
- Work complete
- Fixed
- Closed
 Anyone should be able to enter a New defect, but just because someone thinks “I tawt I taw a defect!” in the system doesn’t mean that the defect is real. In poorly specified software systems QA will often perceive a defect where there is none, the famous functions as designed (FAD) issue.
Anyone should be able to enter a New defect, but just because someone thinks “I tawt I taw a defect!” in the system doesn’t mean that the defect is real. In poorly specified software systems QA will often perceive a defect where there is none, the famous functions as designed (FAD) issue.
Since there are duplicate and phantom issues that are entered into the Bug Tracker, we need to kick the tires on all New defects before assigning them to someone. It is much faster and cheaper to verify defects than to simply throw them at the development team and assume that they can fix them.
 Trust But Verify
Trust But Verify
New defects not entered by QA should be assigned to the QA role. These defects should be verified by QA before the life cycle status is updated to Verified. QA should also make sure that the steps to reproduce the defect are complete and accurate before moving the defect to the Verified life cycle status. Ideally even defects entered by QA should be verified by someone else in QA to make sure that the defect is entered correctly.
 By introducing a Verified state you separate out potential work from actual work. If a bug is a phantom then QA can mark it as Closed it before we assign it to someone and waste their time. If a bug is a duplicate then it can be marked as such, linked to the other defect, and Closed.
By introducing a Verified state you separate out potential work from actual work. If a bug is a phantom then QA can mark it as Closed it before we assign it to someone and waste their time. If a bug is a duplicate then it can be marked as such, linked to the other defect, and Closed.
The advantage of the Verified status is that the intermittent bugs get more attention to figure out how to reproduce them. If QA discovers that a defect is intermittent then a separate field in the Bug Tracker, Reproducibility, should be populated with one of the following values:
- Always (default)
- Sometimes
- Rare
- Can’t reproduce
Note: This means that bugs that can not be reproduced stay in the New state until you can reproduce them. If you can’t reproduce them then you can mark the issue as Closed without impacting the development team.
Assign the Defect to a Role
QA has a tendency to assume that all defects are coding defects — however, the analysis of 18,000+ projects does not confirm this. In The Economics of Software Quality, Capers Jones and Olivier Bonsignour show that defects fall into different categories. Below we give the category, the frequency of the defect, and the business role that will address the defect.
Note, only the bolded rows below are assigned to developers.
| Defect Role Category | Frequency | Role |
| Requirements defect | 9.58% | BA/Product Management |
| Architecture or design defect | 14.58% | Architect |
| Code defect | 16.67% | Developer |
| Testing defect | 15.42% | Quality Assurance |
| Documentation defect | 6.25% | Technical Writer |
| Database defect | 22.92% | DBA |
| Website defect | 14.58% | Operations/Webmaster |
 Defect Role Categories are important to accelerating your overall development speed!
Defect Role Categories are important to accelerating your overall development speed!
Even if all architecture, design, coding, and database defects are handled by the development group this only represents 54% of all defects. So assigning any New defect to the development group without verification is likely to cause problems inside the team.
Note, 25% of all defects are caused by poor requirements and bad test cases, not bad code. This means that the business analysts and QA folks are responsible for fixing them.

Given that 46% of all defects are not resolved by the development team there needs to be a triage before a bug is assigned to a role. Lack of bug triages is the Root cause of ‘Fire-Fighting’ in Software Projects.
The Bug Tracker should be extended to record the DefectRole in addition to the assigned attribute. Just this attribute will help to straighten out the Bug Tracker!
Non-development Defects
Most Bug Tracking systems have a category called enhancement. Enhancements are simply defects in the requirements and should be recorded but not specified in the Bug Tracker; the defect should be Open with a DefectRole of ProductManagement.
Enhancements need to be assigned to product managers/BAs who should document and include a reference to that documentation in the defect. The description for the defect is not the proper place to keep requirements documentation. The life cycle of a product requirement is generally very different from a code defect because the requirement is likely to be deferred to a later release if you are late in your product cycle.
Business requirements may have to be confirmed with the end users and/or approved by the business. As such, they generally take longer to become work items than code defects.
QA should not send enhancements to development without involvement of product management.
Note that 15.42% of the defects are a QA problem and are fixed in the test plans and test cases.
Bug Triage
The only way to correctly assign resources to fix a defect is to have a triage team meet regularly that can identify what the problem is. A defect triage team needs to include a product manager, QA person, and developer. The defect triage team should meet at least once a week during development and at least once a day during releases. Defect triages save you time because only 54% of the defects can be fixed by the developers; correctly assigning defects avoids miscommunication.
Effective bug triage meetings are efficient when the only purpose of the meeting is to correctly assign defects. Be aggressive and keep design discussions out of triages.
 Defects should be assigned to a role and not a specific person to allow maximum flexibility in getting the work done; they should only be assigned to a specific person when there is only one person who can resolve an issue.
Defects should be assigned to a role and not a specific person to allow maximum flexibility in getting the work done; they should only be assigned to a specific person when there is only one person who can resolve an issue.
Assigning unverified and intermittent defects to the wrong person will start your team playing the blame game.
As the defects are triaged, product management (not QA) should set the priority and severity as they represent the business. With a multi-functional team these two values will be set consistently. In addition the triage team should set the version that the defect will be fixed. Some teams like to put the actual version number where a defect gets fixed(i.e. ExpectedFixVersion) I prefer to use the following:
- Next bug fix
- Next minor release
- Next major release
- Won’t fix
 I like ExpectedFixVersion because it is conditional, it represents a desire. Like it (or not) it is very hard to guess when every defect will be fixed. The reality is that if the release date gets pulled in or the work turns out to be more involved than expected the fix version could be deferred (possibly indefinitely). If you guess wrong then you will spend a considerable amount of time changing this field.
I like ExpectedFixVersion because it is conditional, it represents a desire. Like it (or not) it is very hard to guess when every defect will be fixed. The reality is that if the release date gets pulled in or the work turns out to be more involved than expected the fix version could be deferred (possibly indefinitely). If you guess wrong then you will spend a considerable amount of time changing this field.
Getting the Defect Resolved
Once the defects are in the system each functional role can assign the work to its resources. At that point the defect life cycle state is Work In Progress.
All Work complete means is that the individual working on the defect believes that it is resolved. When the work is resolved the FixVersion should be set as the next version that will be released. Note, if you use release numbers in the ExpectedFixVersion field then you should update that field if it is wrong 🙂
Of course the defect may or may not be resolved, however, the status of Work complete acts a signal that someone else has work to do.
If a requirements defect is fixed then the issue should be moved to Fixed and assigned to the development manager that will give the work to his team. Once the team has verified their understanding of the requirement the defect can move from Fixed to Closed.
Work complete means that the fixer believes that problem is resolved, Fixed means that the team has acknowledged the fix!
For code defects the Work complete status is a signal to QA to retest the issue. If QA establishes that the defect is fixed they should move the issue to Fixed. If the issue is not fixed at all then the defect should move back to Open; if the defect is partially fixed then the defect should move to Verified so that it goes back through the bug triage process (i..e severity and priority may have changed).
Once a release is complete, all Fixed items can be moved to Closed.
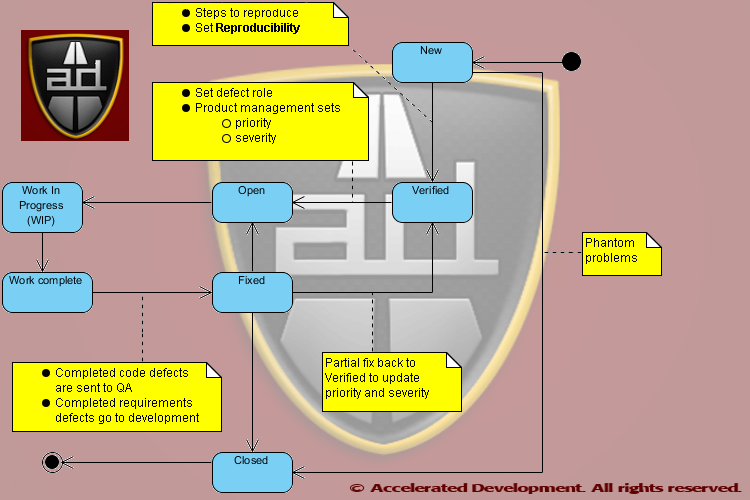
Tracking Defects Caused by Fixing Defects
Virtually all Bug Trackers allow you to link one or more issues together. However, it is extremely important to know why bugs are linked, in most cases you link bugs because they are duplicates.
Bugs can be linked together because fixing one defect may cause another. On average this happens for every 14 defects fixed but in the worst organizations can happen every 4 defects fixed. Keeping a field called ResultedFromDefect where you link the number of the other defect allows you to determine how new defects are the result of fixing other defects.
Summary
Let’s recap how the above mechanisms will help you get out of hell.
- By introducing the Verified step you make sure that bugs are vetted before anyone get pulled into a wild goose chase.
- This also will catch intermittent defects and give them a home while you figure out how often they are occurring and work out if there is a reliable way to produce them.
- If you can’t reproduce a defect then at least you can annotate it as Can’t Reproduce, i.e. status stays as New and it doesn’t clog the system
- By conducting triage meetings with product management, QA, and development you will end up with very consistent uses of priority and severity
- Bug triages will end up categorizing defects according to the role that will fix them which will reduce or eliminate:
- The blame game
- Defects being assigned to the wrong people
- By having the ExpectedFixVersion be conditional you won’t have to run around fixing version numbers for defects that did not get fixed in a particular release. It also gives you a convenient way to tag a defect as Won’t Fix, the status should go back to Verified.
- By having the person who fixes a defect set the FixVersion then you will have an accurate picture of when defects are fixed
- When partially fixed defects go back to Verified the priority and severity can be updated properly during the release.
Benefits of the Process
By implementing the defect life cycle process above you will get the following benefits:
- Phantom bugs and duplicates won’t sandbag the team
- Intermittent bugs will receive more attention to determine their reproducibility
- Reproducible bugs are much easier to fix
- Proper triages will direct defects to the appropriate role
- You will discover how many defects you create by fixing other defects
By having an extended set of life cycle states you will be able to start reporting on the following:
- % of defects introduced while fixing defects (value in ResultedFromDefect)
- % of New bugs that are phantoms or duplicates, relates to QA efficiency
- % of defects that are NOT development problems, relates to extended team efficiency (i.e. DefectRole <> Development)
- % of requirements defects which relates to the efficiency of your product management (i.e. DefectRole = ProductManagement)
- % of defects addressed but not confirmed (Work Completed)
- % of defects fixed and confirmed (Fixed)
It may sound like too much work to change your existing process, but if you are already in Bug Tracker hell, what is your alternative?
Need help getting out of Bug Tracker hell? Write to me at dmahal@AcceleratedDevelopment.ca
Appendix: Importance of Capturing Requirements Defects
 The report on the % of requirements defects is particularly important because it represents the amount of scope shift (creep) in your project. You can see this in the blog Shift Happens. Also, if the rates of scope shift of 2% per month are strong indicators of impending swarms of bugs and project failure.
The report on the % of requirements defects is particularly important because it represents the amount of scope shift (creep) in your project. You can see this in the blog Shift Happens. Also, if the rates of scope shift of 2% per month are strong indicators of impending swarms of bugs and project failure.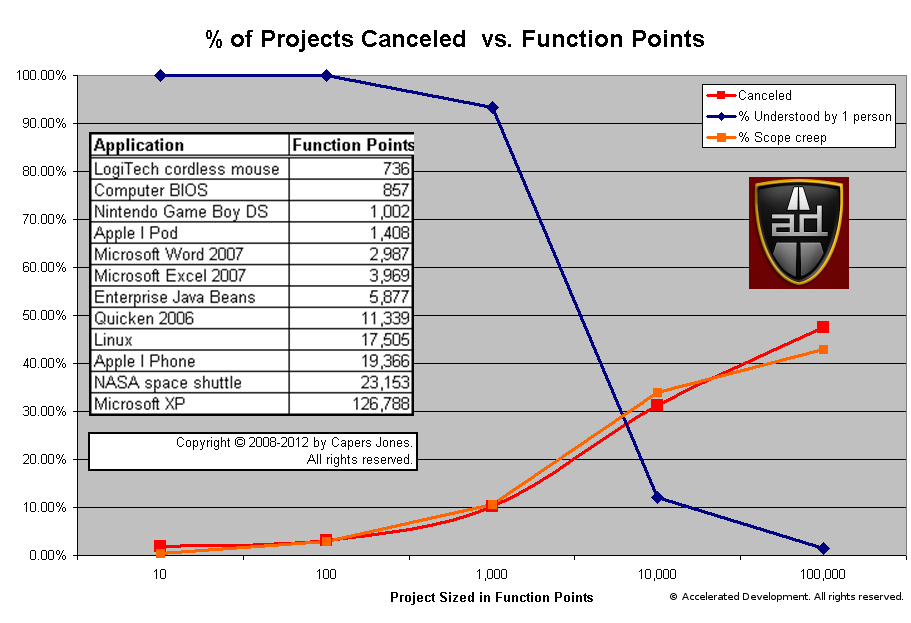 Analysis shows that the probability of a project being canceled is highly correlated with the amount of scope shift. Simply creating enhancements in the Bug Tracker hides this problem and does not help the team.
Analysis shows that the probability of a project being canceled is highly correlated with the amount of scope shift. Simply creating enhancements in the Bug Tracker hides this problem and does not help the team.











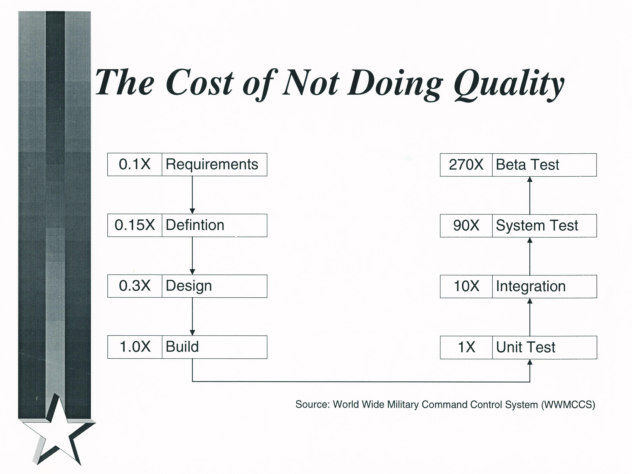

 How many times are you going to rinse and repeat this process until you try something different? If you want to break this cycle, then you need to start collecting consistent requirements.
How many times are you going to rinse and repeat this process until you try something different? If you want to break this cycle, then you need to start collecting consistent requirements.