
 Only the ignorant don’t plan their code pathways before they write them. Unless you are implementing classes of only getter and setter routines code needs to be planned. We talk about The Path Least Traveled The total number of pathways through a software system grow so quickly that it is very hard to imagine their total number.
Only the ignorant don’t plan their code pathways before they write them. Unless you are implementing classes of only getter and setter routines code needs to be planned. We talk about The Path Least Traveled The total number of pathways through a software system grow so quickly that it is very hard to imagine their total number.  If a function X() with 9 pathways calls function Y() which has 11 pathways then the composition function X() ° Y() will have up to 9 x 11 = 99 possible pathways. If function Y() calls function Z() with 7 pathways, then X() ° Y() ° Z() will have up to 693 = 9 x 11 x 7 pathways. The numbers add up quickly, for example a call depth of 8 functions each with 8 pathways means 10.7 million different paths; the number of possible pathways in a system is exponential with the total depth of the call tree. Programs, even simple ones, have hundreds if not thousands (or millions) of pathways through them.
If a function X() with 9 pathways calls function Y() which has 11 pathways then the composition function X() ° Y() will have up to 9 x 11 = 99 possible pathways. If function Y() calls function Z() with 7 pathways, then X() ° Y() ° Z() will have up to 693 = 9 x 11 x 7 pathways. The numbers add up quickly, for example a call depth of 8 functions each with 8 pathways means 10.7 million different paths; the number of possible pathways in a system is exponential with the total depth of the call tree. Programs, even simple ones, have hundreds if not thousands (or millions) of pathways through them. 
Negative vs Positive Assurance
Quality assurance can only come from the developers, not the testing department. Testing is about negative assurance, which is only a statement that “I don’t see anything wrong”; it doesn’t mean that everything is correct, just that they can’t find a problem. Positive assurance which is guaranteeing that the code will execute down the correct pathways and only the developer can do that. Quality assurance comes from adopting solid practices to ensure that code pathways are layed down correctly the first time
Any Line of Code can be Defective
 If there are 10 pathways through a function then there there must be branching statements based on variable values to be able to direct program flow down each of the pathways. Each pathway may compute variable values that may be used in calculations or decisions downstream. Each downstream function can potentially have its behavior modified by any upstream calculation. When code is not planned then errors may cause execution to compute a wrong value. If you are unlucky that wrong value is used to make a decision which may send the program down the wrong pathway. If you are really unlucky you can go very far down the wrong pathways before you even identify the problem. If you are really, really, really unlucky not only do you go down the wrong pathway but the data gets corrupted and it takes you a long time to recognize the problem in the data. It takes less time to plan code and write it correctly than it takes to debug complex pathways.
If there are 10 pathways through a function then there there must be branching statements based on variable values to be able to direct program flow down each of the pathways. Each pathway may compute variable values that may be used in calculations or decisions downstream. Each downstream function can potentially have its behavior modified by any upstream calculation. When code is not planned then errors may cause execution to compute a wrong value. If you are unlucky that wrong value is used to make a decision which may send the program down the wrong pathway. If you are really unlucky you can go very far down the wrong pathways before you even identify the problem. If you are really, really, really unlucky not only do you go down the wrong pathway but the data gets corrupted and it takes you a long time to recognize the problem in the data. It takes less time to plan code and write it correctly than it takes to debug complex pathways.
Common Code Mistakes
 Defects are generally caused either because of one of the following conditions:
Defects are generally caused either because of one of the following conditions:
- incorrect implementation of an algorithm
- missing pathways
- choosing the wrong pathway based on the variables
1) Incorrect implementation of an algorithm will compute a wrong value based on the inputs. The damage is localized if the value is computed in a decision statement, however, if the value is computed in a variable then damage can happen everywhere that value is used. Example, bad decision at node 1 causes execution to flow down path 3 instead of 2. 2) Missing pathways have to deal with conditions. If you have 5 business conditions and only 4 pathways then one of your business conditions will go down the wrong pathway and cause problems until you detect the problem. Example, there was really 5 pathways at node 1, however, you only coded 4. 3a) The last problem is that the base values are correct but you select the wrong pathway. This can lead to future values being computed incorrectly. Example: at node 10 you correctly calculate that you should take pathway 11 but end up going down 12 instead. 3b) You might also select the wrong pathway because insufficient information existed at the time that you needed to make a decision. Example: insufficient information at node 1 causes execution to flow down path 3 instead of 4. The last two issuses (2 or 3) can either be a failure of development or of requirements. In both cases somebody failed to plan…
What if it is too late to Plan
Whenever you are writing a new section of code you should take advantage of the ability to plan the code before you write it. If you are dealing with code that has already been written then you should take advantage of inspections to locate and remove defects. Don’t wait for defects to develop, proactively inspect all code, especially in buggy modules and fix all of the code pathways. Code inspections can raise productivity by 20.8% and quality by 30.8%
Code Solutions
The Personal Software Process (PSP) has a specific focus that every code section should be planned by the developer before it is implemented. That means that you sit down and plan your code pathways using paper or a white board before using the keyboard. Ideally you should spend the first part of your day planning with your colleagues on how best to write your code pathways. The time that you spend planning will pay you dividends in time saved. PSP can raise productivity by 21.2% and quality by 31.2% If you insist on writing code at the keyboard then you can use pair programming to reduce errors. By having a second pair of eyes looking at your code algorithmic mistakes are less likely and incorrect decisions for conditions are looked at by two people. The problem is that pair programming is not cost effective overall. Pair Programming can raise productivity by 2.7% and quality by 4.5% Studies confirm that code sections of high cyclomatic complexity have more defects than other code sections. At a minimum, any code section that will have a high cyclomatic complexity should be planned by two or more people. If this is not possible, then reviewing sections of high cyclomatic complexity can reduce downstream defects. Automated cyclomatic complexity analysis can raise productivity by 14.5% and quality by 19.5% Design Solutions All large software projects benefit from planning pathways at the macroscopic level. The design or architectural planning is essential to making sure that the lower level code pathways will work well. Formal architecture for large applications can raise productivity by 15.7% and quality by 21.8% Requirements Solutions Most pathways are not invented in development. If there is insufficient information to choose a proper pathway or there are insufficient pathways indicated then this is a failure of requirements. Here are several techniques to make sure that the requirements are not the problem. Joint application design (JAD) brings the end-users of the system together with the system architects to build the requirements. By having end-users present you are unlikely to forget a pathway and by having the architects present you can put technical constraints on the end-users wish list for things that can’t be built. The resulting requirements should have all pathways properly identified along with their conditions. Joint application design can raise productivity by 15.5% and quality by 21.4% Requirements inspections are the best way to make sure that all necessary conditions are covered and that all decisions that the code will need to make are identified before development. Not inspecting requirements is the surest way to discovering that there is a missing pathway or calculation after testing. Requirement inspections can raise productivity by 18.2% and quality by 27.0% Making sure that all pathways have been identified by requirements planning is something that all organizations should do. Formal requirements planning will help to identify all the code pathways and necessary conditions, however, formal requirements planning only works when the business analysts/product managers are skilled (which is rare 🙁 ). Formal requirements analysis can raise productivity by 16.3% and quality by 23.2%
Other articles in the “Loser” series
| Want to see more sacred cows get tipped? Check out |  |
| Moo? |
Make no mistake, I am the biggest “Loser” of them all. I believe that I have made every mistake in the book at least once 🙂
References
- Gilb, Tom and Graham, Dorothy. Software Inspections
- Jones, Capers. SCORING AND EVALUATING SOFTWARE METHODS, PRACTICES, AND RESULTS. 2008.
- Radice, Ronald A. High Quality Low Cost Software Inspections.



 developer has an opportunity to plan his code, however, there are many developers who just ‘start coding’ on the assumption that they can fix it later.
developer has an opportunity to plan his code, however, there are many developers who just ‘start coding’ on the assumption that they can fix it later.



 that was pioneered by the Eiffel programming language It would be tedious and overkill to use DbC in every routine in a program, however, there are key points in every software program that get used very frequently.
that was pioneered by the Eiffel programming language It would be tedious and overkill to use DbC in every routine in a program, however, there are key points in every software program that get used very frequently.

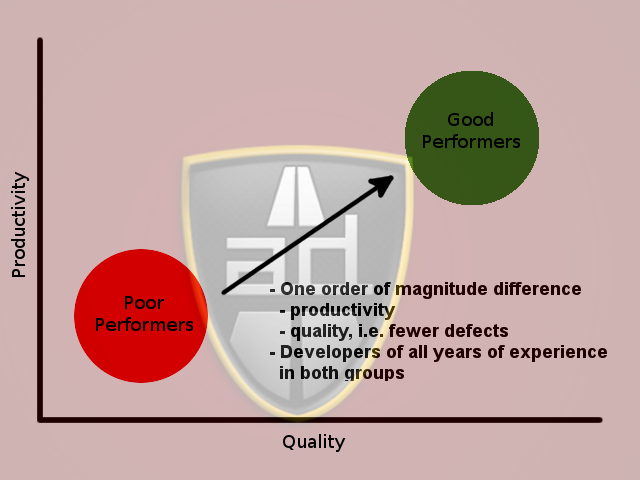 That is the worst programmers and the best programmers made distinct groups and each group had people of low and high experience levels. Whether training helps developers or not is not indicated by these findings, only that years of experience do not matter.
That is the worst programmers and the best programmers made distinct groups and each group had people of low and high experience levels. Whether training helps developers or not is not indicated by these findings, only that years of experience do not matter.



 There are 5 worst practices that if stopped immediately will
There are 5 worst practices that if stopped immediately will 
 To make matters worse, some of the worst practices will cause other worst practices to come into play.
To make matters worse, some of the worst practices will cause other worst practices to come into play.  Friction among managers because of different perspectives on resource allocation, objectives, and requirements. It is much more important for managers to come to a consensus than to fight for the sake of fighting. Not being able to come to a consensus will cave in projects and make ALL the managers look bad. Managers win together and lose together.
Friction among managers because of different perspectives on resource allocation, objectives, and requirements. It is much more important for managers to come to a consensus than to fight for the sake of fighting. Not being able to come to a consensus will cave in projects and make ALL the managers look bad. Managers win together and lose together. Friction among team members because of different perspectives on requirements, design, and priority. It is also much more important for the team to come to a consensus than to fight for the sake of fighting. Again, everyone wins together and loses together — you can not win and have everyone else lose.
Friction among team members because of different perspectives on requirements, design, and priority. It is also much more important for the team to come to a consensus than to fight for the sake of fighting. Again, everyone wins together and loses together — you can not win and have everyone else lose.
 Quality Assurance (QA) is about making a positive statement about product quality. QA is about positive assurance, which is stating, “
Quality Assurance (QA) is about making a positive statement about product quality. QA is about positive assurance, which is stating, “ The reality is that most testing departments simply discover defects and forward them back to the engineering department to fix. By the time the software product gets released we are basically saying, “
The reality is that most testing departments simply discover defects and forward them back to the engineering department to fix. By the time the software product gets released we are basically saying, “ Everyone understand that buggy software kills sales (and start-ups :-)), however, testing is often an after thought in many organizations. When software products take longer than expected they are forwarded to the testing department. The testing department is often expected to test and bless code in less time than allocated.
Everyone understand that buggy software kills sales (and start-ups :-)), however, testing is often an after thought in many organizations. When software products take longer than expected they are forwarded to the testing department. The testing department is often expected to test and bless code in less time than allocated. Properly written tests require a developer not only to think about what a code section is supposed to do but also plan how the code will be structured. If you know that there are five pathways through the code then you will write five tests ahead of time. A common problem is that you have coded n paths through the code when there are n+1 conditions.
Properly written tests require a developer not only to think about what a code section is supposed to do but also plan how the code will be structured. If you know that there are five pathways through the code then you will write five tests ahead of time. A common problem is that you have coded n paths through the code when there are n+1 conditions.
 Since the 1970s we have statistical evidence that one of the best ways to eliminate defects from code is through inspections. Inspections can be applied to the requirements, design, and code artifacts and projects that use inspections can eliminate 99% of the defects injected into the code. Se
Since the 1970s we have statistical evidence that one of the best ways to eliminate defects from code is through inspections. Inspections can be applied to the requirements, design, and code artifacts and projects that use inspections can eliminate 99% of the defects injected into the code. Se  There is
There is  are the best line of defense to remove them. The developer has the best information on what needs to be tested in his code at the time that he writes it. The longer it takes for testing or a customer to discover a code defect the longer the developer will spend in a debugger chasing down the problem.
are the best line of defense to remove them. The developer has the best information on what needs to be tested in his code at the time that he writes it. The longer it takes for testing or a customer to discover a code defect the longer the developer will spend in a debugger chasing down the problem.
 Are you a software professional or not?
Are you a software professional or not?



 For inspections to work, they must be conducted in a non-judgmental environment where the goal is to eliminate defects and improve quality. When inspections turn into witch hunts and/or the focus is on style rather than on substance then inspections will fail miserably and they will become a waste of time.
For inspections to work, they must be conducted in a non-judgmental environment where the goal is to eliminate defects and improve quality. When inspections turn into witch hunts and/or the focus is on style rather than on substance then inspections will fail miserably and they will become a waste of time. Every developer is aware that code inspections are possible, some might have experienced the usefulness of code inspections, however, the fact is that inspections are not optional.
Every developer is aware that code inspections are possible, some might have experienced the usefulness of code inspections, however, the fact is that inspections are not optional. In the physical world it is easier to spot problems because they can be tangible. For example, if you have specified marble tiles for your bathroom and you see the contractor bring in a pile of ceramic tiles then you know something is wrong. You don’t need the contractor to install the ceramic tiles to realize that there is a problem.
In the physical world it is easier to spot problems because they can be tangible. For example, if you have specified marble tiles for your bathroom and you see the contractor bring in a pile of ceramic tiles then you know something is wrong. You don’t need the contractor to install the ceramic tiles to realize that there is a problem.













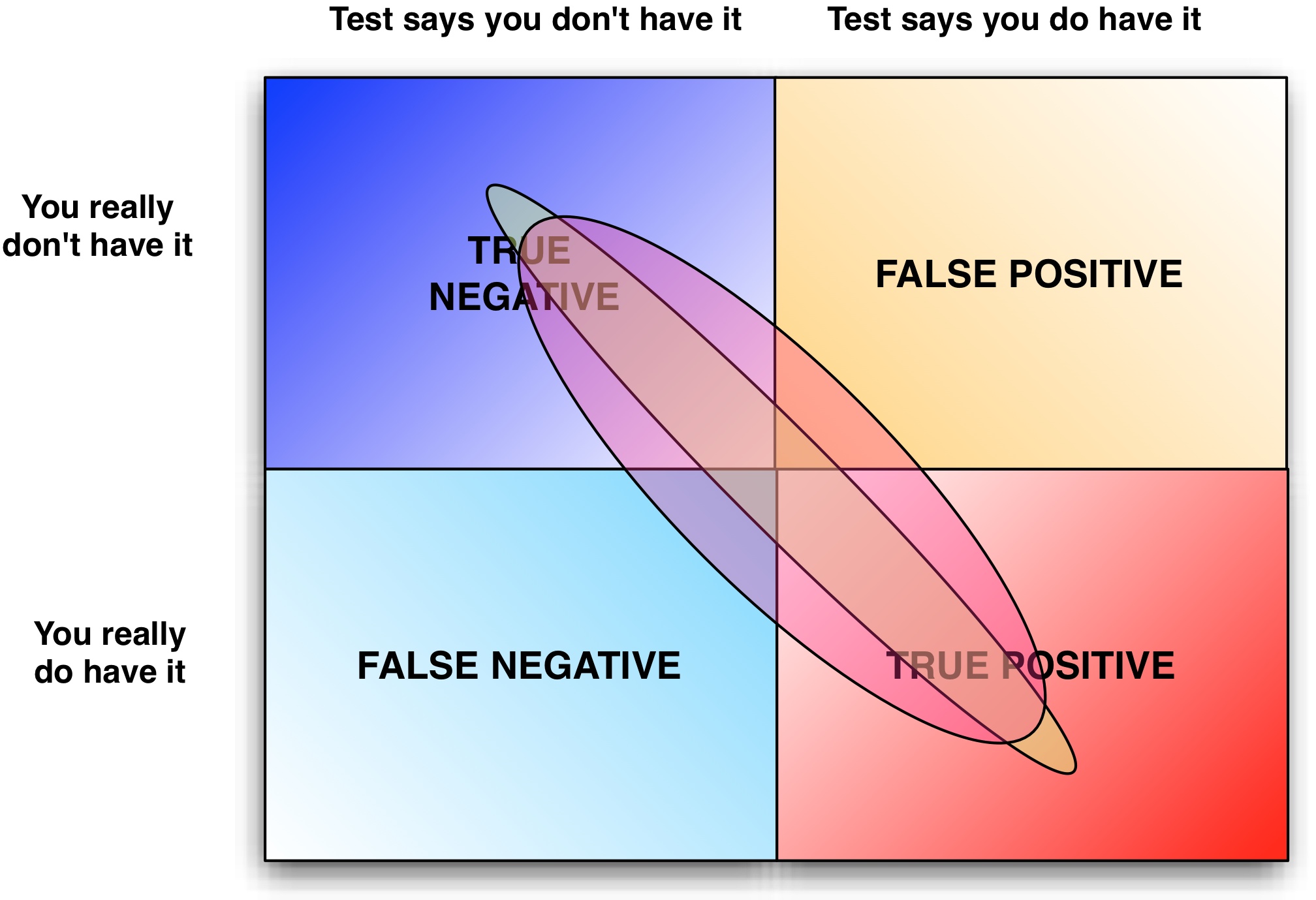 Testing defects occur when the test plan flags a defect that is a phantom problem or a false positive. This often occurs when requirements are poorly documented and/or poorly understood and QA perceives a defect when there is none.
Testing defects occur when the test plan flags a defect that is a phantom problem or a false positive. This often occurs when requirements are poorly documented and/or poorly understood and QA perceives a defect when there is none.


 What Life Cycle States Do We Need?
What Life Cycle States Do We Need?

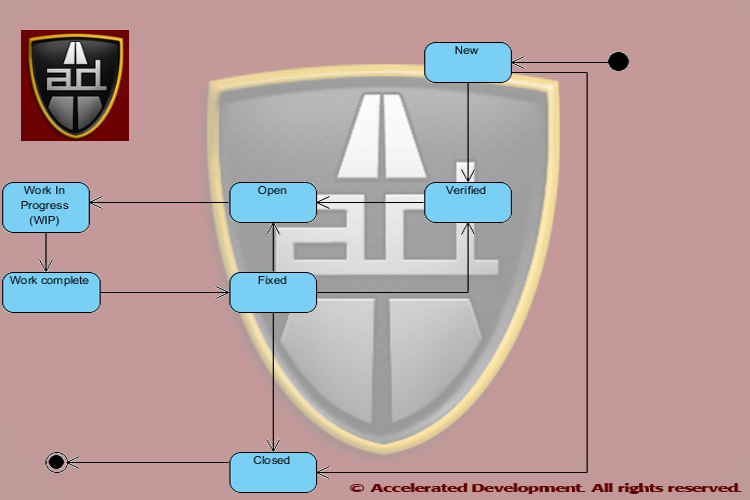

 Trust But Verify
Trust But Verify


 Defects should be assigned to a role and not a specific person to allow maximum flexibility in getting the work done; they should only be assigned to a specific person when there is only one person who can resolve an issue.
Defects should be assigned to a role and not a specific person to allow maximum flexibility in getting the work done; they should only be assigned to a specific person when there is only one person who can resolve an issue. I like
I like 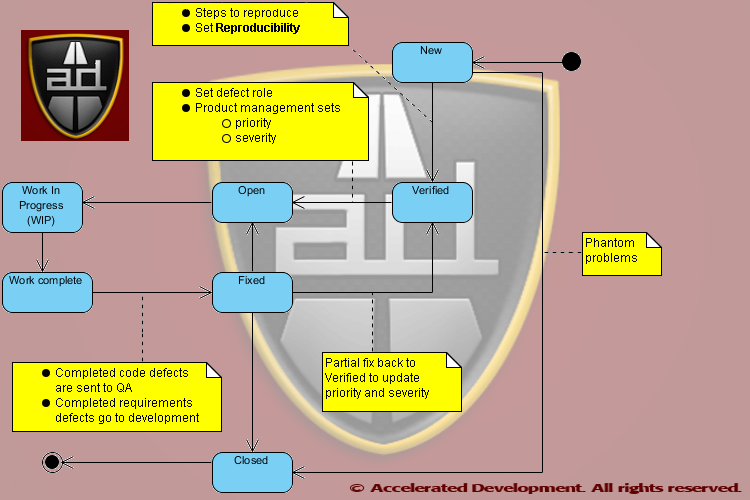

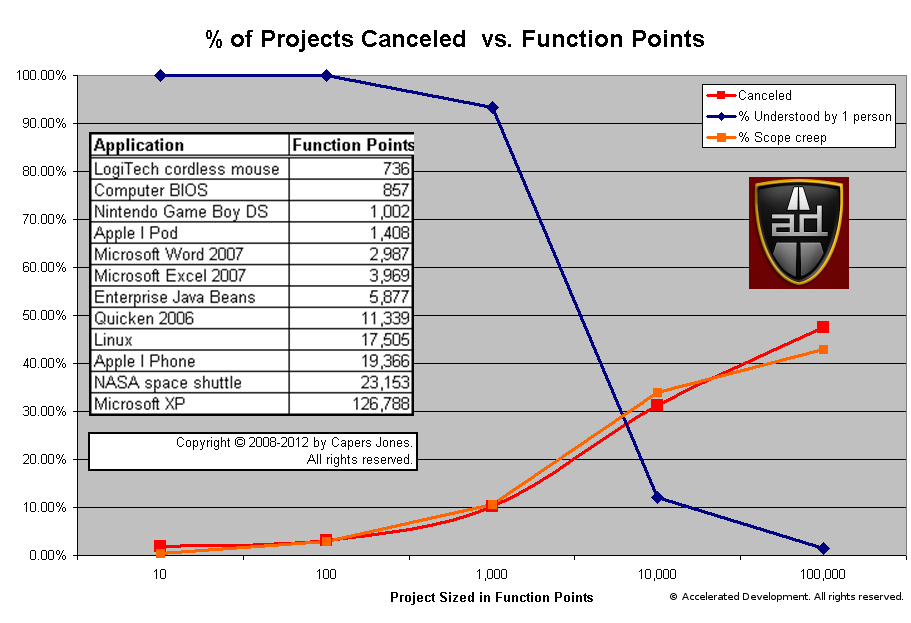 Analysis shows that the probability of a project being canceled is highly correlated with the amount of scope shift. Simply creating enhancements in the Bug Tracker hides this problem and does not help the team.
Analysis shows that the probability of a project being canceled is highly correlated with the amount of scope shift. Simply creating enhancements in the Bug Tracker hides this problem and does not help the team.





















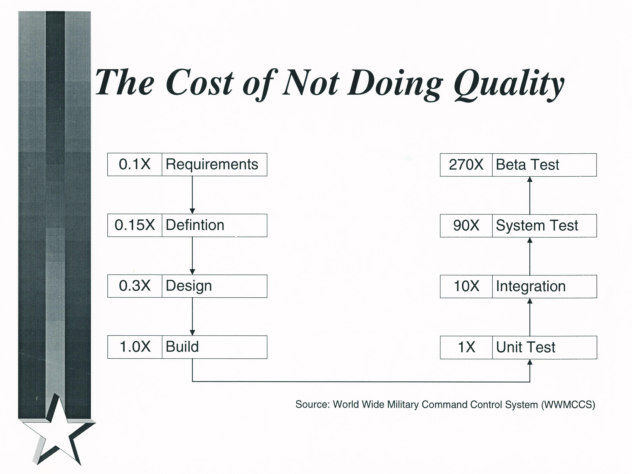

 How many times are you going to rinse and repeat this process until you try something different? If you want to break this cycle, then you need to start collecting consistent requirements.
How many times are you going to rinse and repeat this process until you try something different? If you want to break this cycle, then you need to start collecting consistent requirements.